![[疫情][项目]通过公众号实现一个人员入园收集信息的小功能](/static_1629421268723-978.png)
月光魔力鸭
2021-08-20 14:55 阅读 579 喜欢 0
本篇文章以一个实际的小项目为主题进行从头到尾的讲解实现,该项目总计开发时长约6小时,算是比较快的了,主要是有很多页面或功能都是现成的,直接复制过来的,剩下的就调整下样式、字段内容等。 既然作为一个小项目,那么我们就从需求整理开始依次进行实现,并附带小部分代码或bug处理。
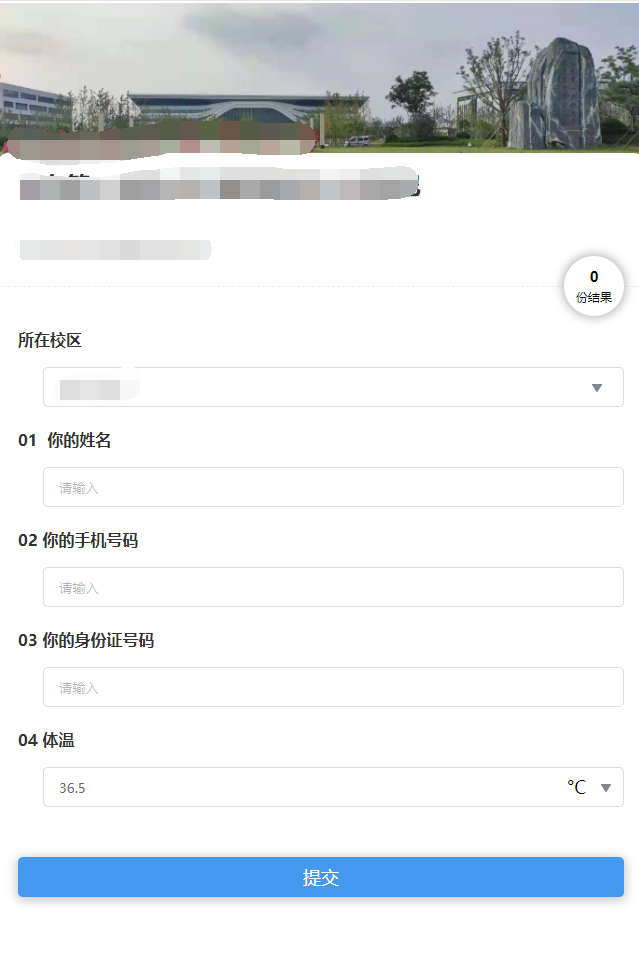
主体:学校 需要在入场的地方放置一个二维码,用户扫码后填写姓名、手机号、提问,然后提交,后台可以看到这些记录,导出入场记录提交给上级。
参考:腾讯文档的调查表
其实,最开始我是主张直接使用腾讯文档的,毕竟这个最简单,而且好多功能都支持,还可以设置,无奈客户最终还是想要开发这个功能。 功能不多,整理下来也就这么几个:
先来几张截图看下最终的效果
数据库 : mysql 服务器端使用nodejs的 thinkjs框架来实现 后台管理使用layui来实现 h5 使用weui来实现 穿透调试使用frp
额 开发过程还是比较流畅的,业务也很简单,没碰到啥问题
有需要的可以直接github自取,不要忘记点赞哦。 github : https://github.com/chrunlee/p_info_collect/tree/main
转载请注明出处: https://chrunlee.cn/article/project-yiqing-wechat-demo.html



