
月光魔力鸭
2020-06-22 22:17 阅读 1760 喜欢 0
对于开发来说,看到别人家的小程序都这么靓,这么顺畅,这么好用,用户又多... 自然是眼馋的..用户馋不来,可以先馋他的身子..啊不,代码啊。
那么看到比较好看的微信小程序,到底怎么才能拿到手去观摩学习下呢..这里给大家来个教程。
关联文章: 微信小程序反编译之electron自动更新 软件获取: https://shop.licran.com/index/detail/a5ec6165-7f4f-4b8e-bf39-51559ed48396.html
在微信中,我们进入小程序后就可以看到小程序的界面和功能,那么怎么拿到这些代码 呢。 其实,微信在运行小程序的时候,会先把小程序下载到本地,然后去运行,机会来了,既然下载到本地了,那么我们就能拿到这些数据。
android的文件路径是/data/data/com.tencent.mm/MicroMsg/xxx/appbrand/pkg/ ,在这里,我们就能发现后缀为.wxapkg的压缩包,实际上就是小程序的包。
这个包实际上是二进制的包,根据规则进行解码出数据和文件的。
以下是用nodejs实现的一个比较简单的解码规则。
/***
* 通过读取文件流获取文件内的各个文件数据
*/
let filePath = '../dxmtk.wxapkg';
let fs = require('fs');
let path = require('path');
//获取头部信息
let buffer = fs.readFileSync(filePath);
console.log(buffer);
//校验文件完整性
let first = buffer.readUInt8(0).toString(16);
let infoCount = buffer.readUInt32BE(5);
let dataCount = buffer.readUInt32BE(9);
let last = buffer.readUInt8(13).toString(16);
console.log(first,infoCount,dataCount,last);
//拆解文件
let infoBuffer = buffer.slice(14,infoCount+14);
let fileCount = infoBuffer.readUInt32BE(0);
let start = 4;
for(let i=0;i<fileCount;i++){
let nameCount = infoBuffer.readUInt32BE(start);
start+=4;
let name = infoBuffer.toString('utf8',start,start+nameCount);
start+=nameCount;
let startpos = infoBuffer.readUInt32BE(start);
start += 4;
let size = infoBuffer.readUInt32BE(start);
start += 4;
//将文件读取
let fileName = path.basename(name);
fs.writeFileSync(path.join(__dirname,'files',fileName),buffer.slice(startpos,startpos+size))
}
运行后,我们就能看到解出的文件内容了,如下:

当然,到了这一步,算是开了个头,后面还要根据内容进行文件夹分类,然后根据html解密还原出js json wxml wxss 等文件才算最终结果,不然还是没得看哦。
当然,微信小程序解密主要还是为了学习观摩大婶们的制作,更好的提升自己,同时..最重要的还是要多加练习哦..
最终解密出的样式如下:
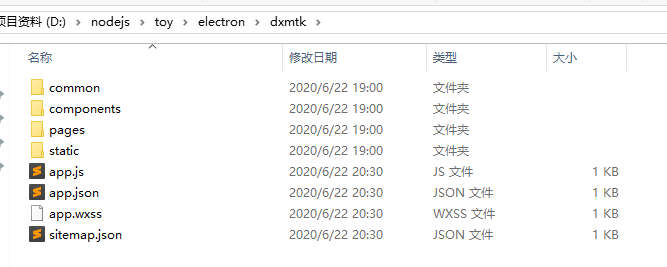
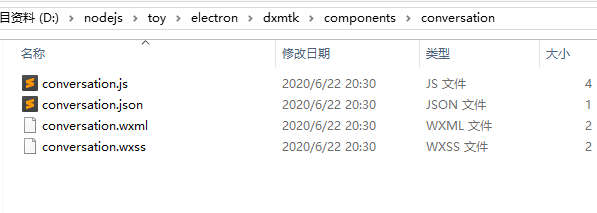
当然,最后js是压缩后的,只是做了下美化,已经没办法再回到最初了..就像已经发生的事,已无法改变..除非联系作者 o(∩_∩)o 哈哈 最近正好在学electron,便做了一个桌面端的程序...简单的要死,就当electron开个quick start 吧。
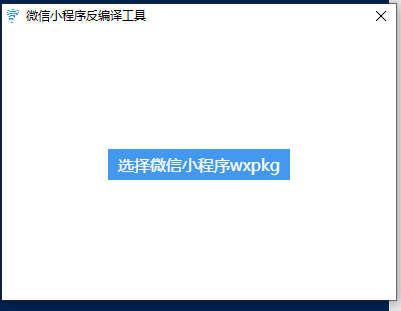
关于微信小程序的解密反编译,我也是一时搞一搞,站在巨人的肩膀上,来实现的 .
转载请注明出处: https://chrunlee.cn/article/wx-miniapp-unpack.html



