
月光魔力鸭
2021-12-22 11:06 阅读 744 喜欢 0
我们项目一直在使用puppeteer 生成pdf ,整体的思路是没有问题的,而且在开发环境运行了好久了,但是部署后总会有各种各样的报错。各种so文件找不到等等 。
今天以 libasound.so.2为例子,如何查找并解决这类问题。
之前的时候出现这类问题只能去网上找类似的解决方案,最近看了一篇文章,发现原来还可以这么做。
当我们缺少某个so文件或找不到的时候,应该安装哪个包?这个对于我来说是一脸懵逼的,我们可以在这个网站上进行搜索。
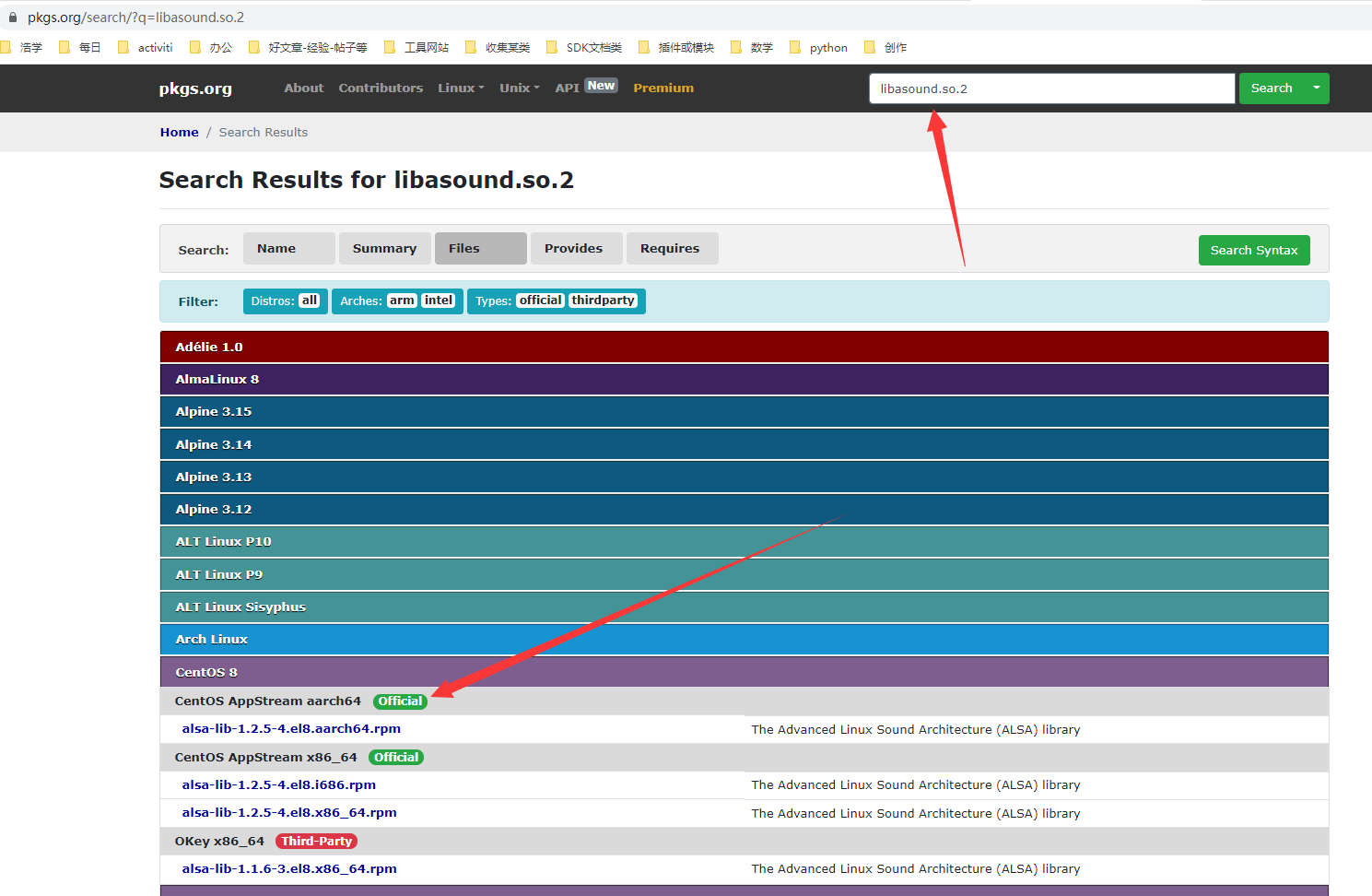
输入我们要查找的文件,找到对应的系统版本和包,点击后进入。
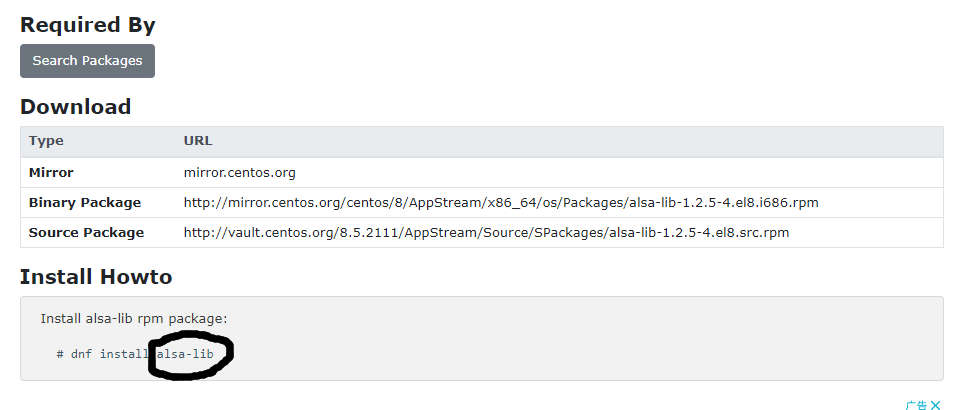
然后安装下alsa-lib 在试试应该就可以了。
转载请注明出处: https://chrunlee.cn/article/puppeteer-so-found.html



