
月光魔力鸭
2018-09-18 14:51 阅读 1655 喜欢 4
从豆瓣转到网易云后,发现了不少好听的歌曲,然鹅..当我想把这些歌拿下来扔车上听的时候发现竟然不允许下载..能听不能下?这不科学,作为一名程序猿,必然要迎难而上啊.
2019年3月14日补充:
在经过了多次使用下载后,发现其实老是要找到源码,还要配置什么的,也是很麻烦的,最终,把这个做成了一个cli 命令行工具,只需要在某个文件夹内打开cmd,输入十几个字符就搞定了。(大写的注意:使用的时候一定要有安装nodejs环境哈,安装超级简单。)
npm install music-163-load -g //一定要全局安装哦,不然每次使用都很麻烦。
//然后在你要保存音乐文件的文件夹内,右键打开命令行,输入以下回车即可,
// -i 后面的是歌单的ID,如果不知道的话,可以在web上打开连接,后面地址上就有写的,
//例如:https://music.163.com/#/playlist?id=2613099530
download -i 2613099530
如果只是想下载某一首歌曲的话,其实也不需要写代码的,毕竟浏览器有很多功能已经可以拿到文件了,但是如果想大量的下载,这种重复劳动就需要扔给程序去做了。
如果是客户端的话,可以右键拿到单曲链接,然后在浏览器打开。如下:
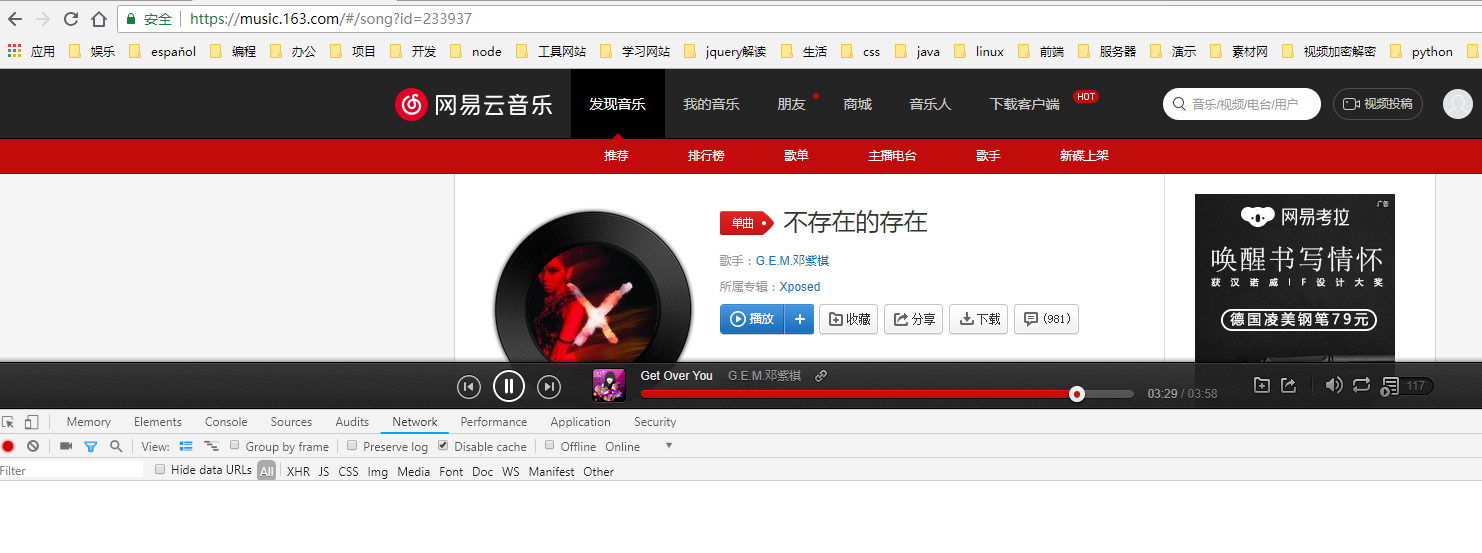
在浏览器中输入链接后,进入页面,然后按下F12后,打开控制台,然后点击network进入该TAB页面。
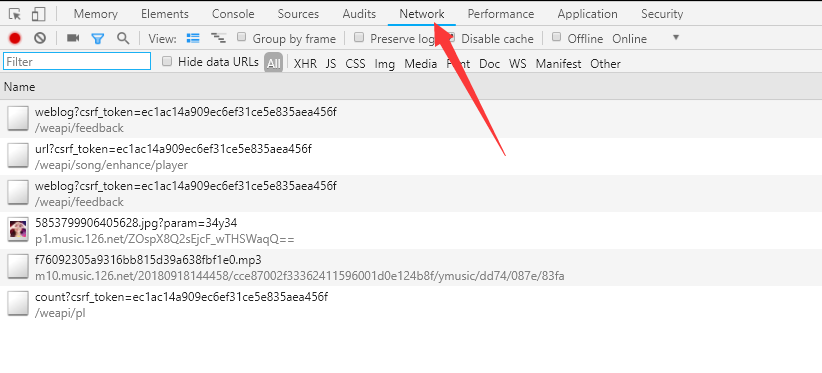
然后点击播放按钮,查看network中就会有该音乐的播放地址。
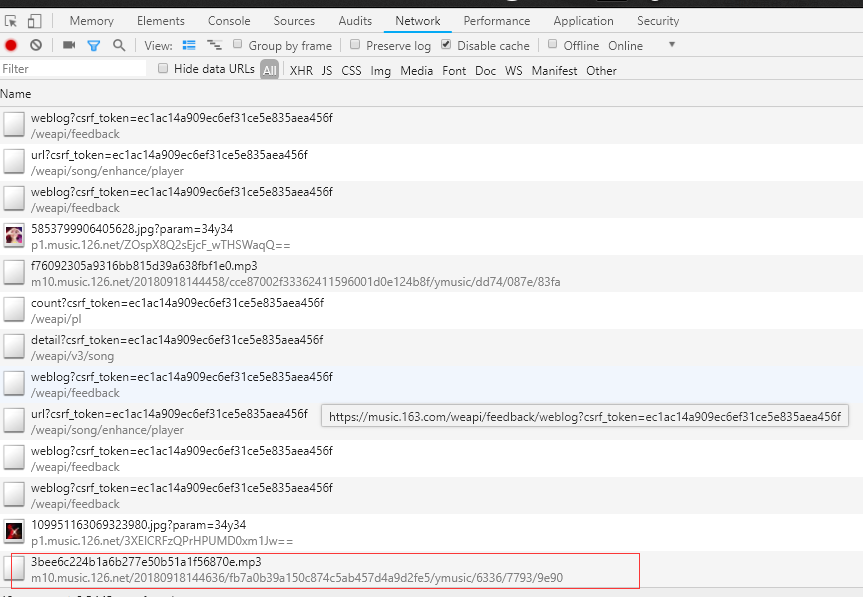
点击该链接,打开后,复制下mp3的播放地址,另开一个窗口输入后即可播放,右键即可另存为本地。
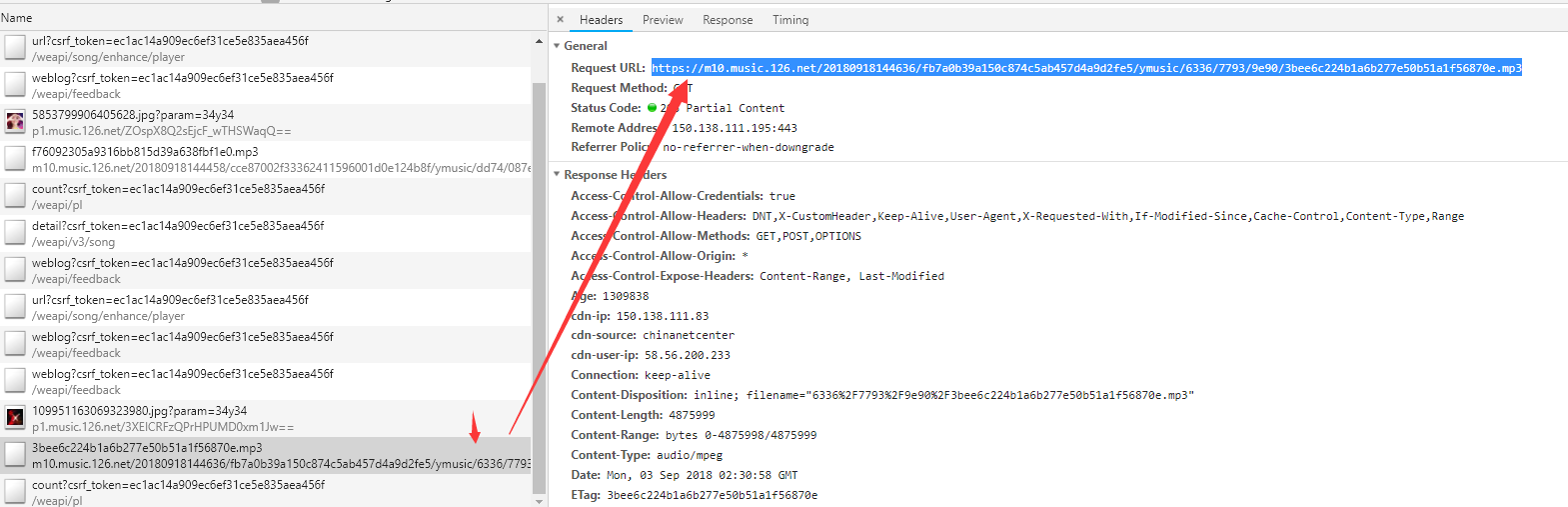
以上操作即可将单曲音乐的文件下载下来,如果不怕麻烦,也可以按照如此的操作,将整个歌单的歌曲文件全部下载下来。
当然,作为一名程序员,决不允许这样的劳动浪费行为。
以下为专业知识,需要至少了解js nodejs 相关的知识,以及少量代码编写操作。
github 上有一个网易云音乐的API接口服务,地址如下:https://github.com/chrunlee/netmusic-node
通过git下载到本地后,启动,然后作为API服务器用来请求调用获取数据使用的。
我这里提供一个我用的,各位在使用的时候,请节制,我也不希望被封IP以后用不了,希望不要用在自动爬取下载的程序上,只是自己使用下载歌单用下就行。http://music.byyui.com/
由于这个工具只是自己平时使用,也没有放在github上,所以,这里只是贴下几个核心代码,大家可以参考下。
// api.js
// var api = 'http://localhost:3000';
var api = 'http://music.byyui.com';
//获得歌单
var superagent = require('superagent');
function MusicLoad ( opt ){
var _default = {
isSingle : false,
getListUrl : api+'/v1/playlist/detail',
getSingleInfo : api+'/v1//music/detail',
getUrl : api+'/v1/music/url',
fs : require('fs'),
url : require('url'),
http : require('http'),
async : require('async')
};
this.opt = Object.assign(_default,opt);
this.init();
}
MusicLoad.prototype.init = function(){
var that = this,opt = that.opt;
if(opt.isSingle){
that.getUrl(that.opt.id,null,function(){
console.log('下载完毕.');
});
}else{
that.getList();
}
}
MusicLoad.prototype.getList = function( ){
var that = this;
superagent.get(that.opt.getListUrl+'?id='+that.opt.id+'&limit=300').end(function(err,res){
if(err){
console.log('无法获取歌单')
return;
}
var txt = res.text;
var data = JSON.parse(txt);
var list = data.playlist.tracks;
console.log(list.length);
console.log('获得'+data.playlist.creator.nickname+'的歌单,共计歌曲:'+list.length+'首');
if(list.length > 0){
//循环,获得一首,下载一首
var data = list.map(function(item){
return {
id : item.id,
name : item.name
};
});
//开始判断
if(that.opt.start !== 0){
data = data.slice(that.opt.start,data.length);
console.log('从第'+that.opt.start+'处开始下载,共计'+(data.length - that.opt.start));
}
that.list = data;
that.startLoad();
}else{
console.log('对不起,这个歌单没有歌曲下载。');
}
});
}
MusicLoad.prototype.startLoad = function(){
var that = this;
var list = that.list,async = that.opt.async;
async.mapLimit(list,1,function(item,cb){
that.getUrl(item.id,item.name,cb);
},function(){
console.log('全部下载完成;');
});
}
MusicLoad.prototype.getUrl = function(id,name,cb){
var that = this;
var target= that.opt.getUrl+'?id='+id+'&br=320000';
console.log(target);
superagent.get(target).end(function(err,res){
if(err){
console.log(err);
cb(err,null);
return;
}
var data =JSON.parse(res.text);
var url = data.data[0].url;
if(typeof url == 'string'){
that.download({id : id,name : name,url : url},cb);
}else{
console.log('没有获得该歌曲的URL');
cb(null,null);
}
});
}
MusicLoad.prototype.download = function( item,callback ){
var download = this.opt.download,fs = this.opt.fs,url = this.opt.url,http = this.opt.http;
var href = item.url,
myHref = url.parse(href);
var host = myHref.host,pathname = myHref.pathname;
var http_client = http.request({
hostname: host,
method: 'GET',
path: pathname,
headers: {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'Accept-Language': 'zh-CN,zh;q=0.8,gl;q=0.6,zh-TW;q=0.4',
'Connection': 'keep-alive',
// 'Content-Type': 'application/x-www-form-urlencoded',
// 'Referer': 'http://music.163.com',
'Pragma':'no-cache',
'Host': host,
'User-Agent': 'Mozilla/5.0 (iPhone; CPU iPhone OS 9_1 like Mac OS X) AppleWebKit/601.1.46 (KHTML, like Gecko) Version/9.0 Mobile/13B143 Safari/601.1'
}
}, function(res) {
res.on('error', function(err) {
//回调,报错
callback(err,null);
});
var fileBuffer = [];
res.on('data',function(chunk){
fileBuffer.push(new Buffer(chunk));
});
res.on('end',function(){
var total = Buffer.concat(fileBuffer);
fs.appendFile(download+'/'+(item.name || item.id) +'.mp3',total,function(err){
console.log('歌曲下载完成:'+item.name);
callback(null,'over');
});
});
});
http_client.end();
}
var Down = function( opt ){
new MusicLoad(opt);
}
module.exports = Down;
以上api.js 为调用API服务的工具类,包括下载以及获取数据,下面的是调用api.js的入口函数:
//app.js
//引入api.js文件
let api = require('./api');
//调用
api({
isSingle : false,//是否是单曲
id : '87950133',//单曲ID或者歌单ID
start : 0,//从第几个开始下载
download : 'f:/redmusic/'//歌曲保存位置
});
console.log('开始下载歌曲..成功率不高');
保存好后,执行node app 即可。
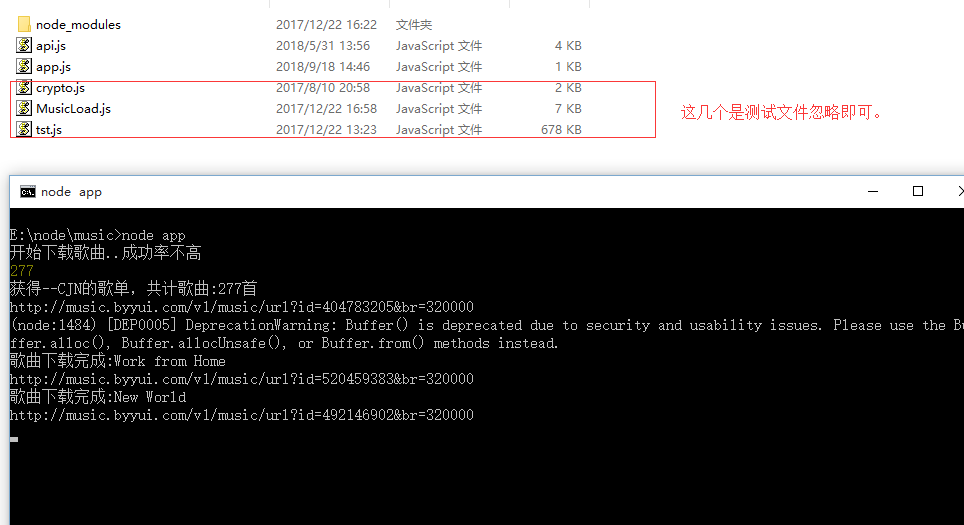
以上,仅作为研究学习使用。
转载请注明出处: https://chrunlee.cn/article/music-163-download.html



